
生成AIの正体は「関数」である
関数とは「入力→出力の箱」
中学校で習った y = 2x + 3 のような式を覚えていますか?
x にある値を入れると、y が1つ返ってくる。
これが関数です。
もっとシンプルに言えば、「何かを入れたら、何かが出てくる箱」のことです。
料理を想像してみましょう。
料理のレシピもこの「箱」と同じ構造をしています。
例えば、卵2個、砂糖30g、牛乳100ml …. という入力を入れると、プリンという出力が返ってくる。
「入力に対して出力を返すルール」、それが関数です。
そしてChatGPTなどの生成AIも同じです。
質問(入力)を入れると、回答(出力)が返ってくる。
画像生成AIならプロンプト(入力)を入れると、画像(出力)が出てくる。
つまり、生成AIの正体も、ただの関数だと解釈できるわけです。
ただし、「めちゃくちゃ複雑で巨大な関数」です。
関数は「入力を受け取って出力を返す装置」
ここで大事なのは、AIを「知能を持った何か」として見るんじゃなくて、「入力を受け取って出力を返す装置」として見ることです。
「知能」って言葉を使うと、なんだか意識があるように感じちゃいますよね。
でも実際には、AIは「学習したパラメータ」(調整された数値の集まり)に基づいて、確率的に「次に来そうな言葉」を選んでいるだけなんです。
AIの中身は「小さな関数の積み重ね」
では、この巨大な関数の中身はどうなっているのでしょうか。
AIの内部は「層」という処理ステップが何層も重なっています。
具体的には、こんな流れです。
- ステップ1: 入力(テキスト)を数値に変換 →
x - ステップ2: 第1層で変換:
h₁ = σ(W₁x + b₁) - ステップ3: 第2層で変換:
h₂ = σ(W₂h₁ + b₂) - ステップ4: …(何十層も続く)
- ステップ5: 最後に出力(テキスト)に戻す
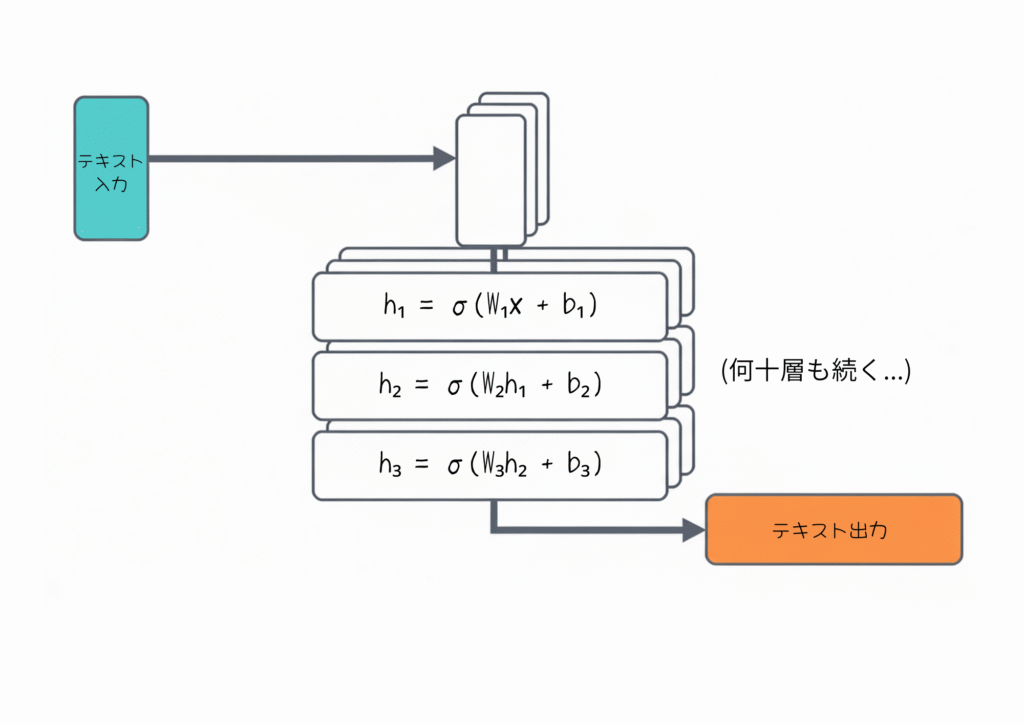
ここで W は「重み」、σ は「活性化関数」と呼ばれるもので、要は「小さな関数を何層も重ねている」んです。
前の関数の出力が次の関数の入力になり、それが連鎖して最終的な出力を得る。
料理で言えば、「下ごしらえ→炒める→煮る→盛り付け」みたいな、工程の連続ですね。
ひとつひとつの工程はシンプルでも、積み重ねることで複雑な料理が完成する。
AIも同じで、層を重ねることで非常に複雑な関数を形成しているのです。
「正解の関数」の中身は誰にもわからない
ここでひとつ問題があります。
この関数って、実際に作れるんでしょうか?
先のプリンの例では、オーブンの温度、材料のメーカー、調味料の量 … など、あらかじめ手順(ルール)が「完璧に」決まっていたら作ることはできそうです。
ただし、もしこのルールが全くわからない未知のものだったとしたら … ?
このような問題を考える場合、一般的に、私たちの手元にあるのは「データ(入力)とその答え(出力)」だけです。
- 何枚かの実際の猫の画像と、「猫」であるという答え
- 何枚かの実際の犬の画像と、「犬」であるという答え
この情報だけで、あらゆる猫と犬を判別するロジックを正確に数式化しプログラムで書く … これは至難の業です。
というか、おそらく無理です。
ではどうするか。
ここで登場するのが「関数近似」という考え方です。
「だいたい正解」を作る技術 = 関数近似という考え方
料理のレシピを思い出してください。
完璧に再現できなくても「だいたいプリン」はできますよね。
オーブンの温度がちょっと違っても、材料のメーカーが違っても、食べれば十分プリン。
これと同じことを数学でやるのが「関数近似」という考え方です。
関数近似とは、「複雑な関数を、もっと扱いやすい形で『だいたい再現する』技術」。
完璧に一致しなくても、実用上十分な精度で元の関数を表現できればそれでいい。
生成AIでは、この考え方が重要になってきます。
関数近似ってどういうこと? 数学の具体例:テイラー展開
数学の具体例を見てみましょう。たとえば、こんなことを考えてみてください。
- 本物の関数:
y = sin(x)(サイン関数、波みたいな曲線) - 近似する関数:
y ≈ x - x³/6 + x⁵/120(多項式)
この近似式は、テイラー展開という手法で作られたもので、この例では、x = 0 付近では「ほぼ同じ曲線」を描きます。(興味がある方は調べてみてください)
完璧に一致はしないけど、局所的には「だいたい合ってる」。
そして式の項を増やせば増やすほど、精度が上がっていく。
AIも「だいたい正解」を狙っている
生成AIもまったく同じです。
猫と犬を完璧に見分ける「神様しか知らない未知の正解関数」がどこかに存在するとして、その中身を正確に数式で書き下すことは誰にもできません。
ただし、我々の理解できる範囲の小さな関数を、「複雑に」「いくつも」組み合わせていくことで、手元のデータから、正解に近い答えを出すような「似たような関数」を無理やり作ることはできる、というわけです。
ChatGPTのような生成AIは「完璧な答え」を返しているわけではありません。
「入力に対して、こういう出力が返ってくる確率が高い」という確率の割り振りを学習していて、その中から最もそれらしい答えを選んでいるのです。
世界中の言語パターンを「だいたい再現できる関数」を、AIは学習しているんですね。
理論的背景:どんな関数でも近似できる
パラメータを増やすほど賢くなる 〜 スケーリング則
「なぜGPT-5はGPT-4より賢いのか?」
理由はいくつかあると思いますが、多くの人が「モデルのパラメータ数が増えたから」と答えるんじゃないでしょうか。で、おそらくこの答えは正しいです。
厳密には、GPT-4もGPT-5もパラメータ数は非公開です
しかし、ここではもう一歩踏み込んでみましょうか。
「モデルのパラメータ数が増えるとなぜ賢くなるのか?」
テイラー展開で項数を増やすと精度が上がるように、AIもパラメータ(重みの数)を増やすと精度が上がります。
これは「スケーリング則」と呼ばれ、OpenAIの研究(Kaplan et al., 2020)によって数学的に確認されています。
この研究によると、言語モデルの性能は「パラメータ数に対して、べき乗則(スケーリング則)に従って向上」し、次のような関係が成り立つと述べられています。
E ∝ N^(-α)E:誤差( = 小さいほど賢いという指標)α:約0.07(実験で得られた値: Kaplan et al. (2020))N:パラメータ数
たとえば、パラメータ数を10倍にすると、誤差は約 10^(-0.07) ≈ 0.87 倍になる。
つまり、スケーリング則によれば、理論上は「大きくすればするほど賢くなる」わけです。
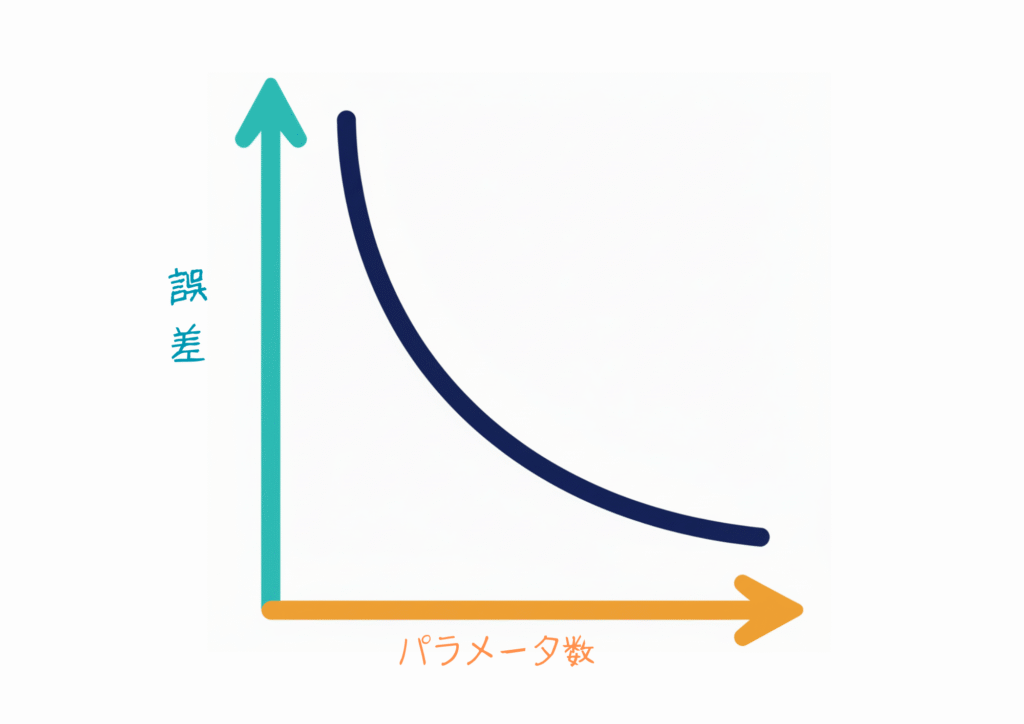
層を深くすること = 関数の表現力UP
さらに、ただパラメータを増やすだけでなく、層を深くすることも重要です。
層を深くすることで、AIは高次の非線形性(複雑な曲線や関係性)を表現できるようになります。
たとえば、1層のネットワークは「直線や単純な曲線」しか表現できないけど、10層、100層と深くしていくと、「めちゃくちゃ複雑で巨大な関数」を表現できるようになるというわけです。
これが「深層学習(ディープラーニング)」という名前の由来でもあります。
万能関数近似器としてのニューラルネットワーク
多くの生成AIモデルは、ニューラルネットワーク(以下、「NN」と呼称)という構造を持ちますが、「NNはどんな関数でも近似できる」というトンデモ理論も存在します。
これは普遍性定理と呼ばれるもので、「十分な数のニューロン(計算ユニット)を持つ「NN」は、どんな連続関数でも任意の精度で近似できる」という数学的な定理です。
この定理によると、「NN」は理論上、どんな関数でも「だいたい再現」できる。
つまり、「NN」は理論上「万能の関数近似器」だというわけです。
数学で見ると「賢さ」も「限界」も見えてくる
「結局、AIは数学的な関数なんだ」と思えると、見方が少し変わってくるかもしれません。
AIの「賢さ」の正体
AIの「賢い」は「関数の近似精度が高い」と解釈できます。
- 質問に対して、自然な答えを返す
- 画像のプロンプトに対して、期待通りの絵を描く
- 翻訳が自然
これらはすべて、入力と出力の「本来誰にもわからない真の関係」を高精度で近似している、という理解で説明できますね。
また、AIの「創発的な振る舞い」も、この高精度近似論で、一部説明が可能という見方もあるようです。
「GPTが、突然数学の問題を解けるようになった」という事象について、パラメータ数が増えたことで関数が表現できるパターンの種類が爆発的に増え、学習データにない組み合わせにも対応できるようになった、などと説明されることもあるようです。
ただし創発の完全な解明はまだされていないようですので、ここは参考程度に留めておきましょう。
AIの「限界」の正体
同時に、限界も見えてきます。
関数近似はあくまで「近似」であって「完全な再現」ではないからです。
- 学習データにないパターンは苦手:関数は、学習したデータの範囲でしか近似できない
- 計算資源が必要:パラメータを増やすには、膨大な計算とメモリが必要
- 誤差はゼロにならない:どんなに大きくしても、理論上ゼロにならない → 完璧な再現は不可能
これらは、数学的に見ると当然のことです。
関数近似は、あくまで「近似」であって、「完全な再現」ではないですからね。
まとめ:AIは「関数」、そして「付き合い方」が見えてくる
生成AIの正体は、「めちゃくちゃ複雑で巨大な関数」でした。
入力に対して出力を返す「関数」であり、その正解の関数は誰にも書けないから「近似」する。
パラメータを増やすほど精度が上がり(スケーリング則)、層を深くするほど複雑なパターンを表現できる。
しかし近似である以上、完璧は存在しない。
AIは「知能」ではなく「関数」。
そう捉えることで、その賢さも限界も、ずっとクリアに見えてきませんか。
数学観点から見た結論
- AIは知能ではなく「関数」:入力と出力の写像として理解できる
- 「大きいほど賢い」は数学的事実:スケーリング則により、パラメータ数と性能は相関する
- どんな関数も近似できる:だいたいの正解を出すだけなら、理論上どんな関数でも作れる
- 「完璧」は存在しない:関数近似の限界として、誤差は必ず残る
関連する数学分野
- 統計学:条件付き確率、期待値、損失関数
- 線形代数:ベクトル空間、行列演算、ノルム
- 解析学:関数近似、テイラー展開、収束
- 最適化理論:勾配降下法、バイアス‑バリアンス・トレードオフ
- 関数解析:普遍性定理、活性化関数の非線形性
参考文献・出典
- Kaplan et al. (2020). “Scaling Laws for Neural Language Models”. arXiv:2001.08361. https://arxiv.org/abs/2001.08361
- Cybenko, G. (1989). “Approximation by superpositions of a sigmoidal function”. Mathematics of Control, Signals and Systems, 2(4), 303-314. https://doi.org/10.1007/BF02551274
- Goodfellow, I., Bengio, Y., & Courville, A. (2016). “Deep Learning”. MIT Press. https://www.deeplearningbook.org
- Wikipedia「統計的学習理論」 https://ja.wikipedia.org/wiki/統計的学習理論
- Wikipedia「テイラー展開」 https://ja.wikipedia.org/wiki/テイラー展開
- Wikipedia「近似論」 https://ja.wikipedia.org/wiki/近似論