
「プロンプトのコツ」だと思っていた頃の見え方
「プロンプトを工夫すると、AIの精度が上がる」
これ、生成AIを使っている人なら誰でも経験してますよね?
たとえば、「レポートを書いて」とだけ頼むと、なんだか的外れな長文が返ってくるのに、
「高校生向けに、200字で要約して」
と伝えると、思った通りのいい感じの回答が返ってくる。
この現象を前にして、多くの人はこう考えていると思います。
- 具体的に書けばいいらしい
- 役割を設定するといいらしい
- 例を付けると精度が上がるらしい
つまり、プロンプトエンジニアリングって「コツの集まり」と捉えている人が多い気がします。
「こう書けばうまくいく」というレシピ集のような感覚です。
実際、ネットを検索すると「プロンプトのテンプレート集」みたいな記事がたくさん出てきます。
それをコピペして使えば、確かにある程度は精度が上がる。
でも、なぜそれで精度が上がるのかと聞かれるとどうでしょうか。
「具体的に書くと良い」
それはわかる。でも、どのくらい具体的にすればいいのか?何を具体的にすればいいのか?
そこの判断基準が「コツ」だけだと、なかなか安定しないんです。
これには、もう少し奥に、すっきりした原理があります。
その原理がわかると、テンプレートに頼らなくても自分でプロンプトを組み立てられるようになるかもしれません。
ベイズ推論という視点を入れると、景色が変わる
ここでベイズ推論という考え方を少しだけ覗いてみます。
ベイズ推論は、「新しい情報を得たら、それに応じて確率の見積もりを更新する」という統計学の考え方です。
18世紀の数学者トーマス・ベイズにちなんで名付けられたもので、現代の機械学習やデータ分析でも広く使われています。
ベイズの定理を式で書くと、こうなります。
P(仮説|データ) = P(データ|仮説) × P(仮説) / P(データ)
これは
データを観測した後に、仮説がどれくらいもっともらしいかは、そのデータが仮説のもとで起きやすいかどうかと、仮説自体のもっともらしさで決まる
ということを表しています。
日常の中のベイズ推論
難しく見えるかもしれませんが、実は私たちは日常的にこれをやっているんですね。
朝起きて「今日は晴れかな?」と思っていたら(事前の見積もり)、窓の外の道が濡れていた(新しい情報)。
それで「夜中に雨が降ったんだな」と考えを更新する(更新された見積もり)。
あるいは、友人が「おすすめの映画がある」と言ったとき。
映画好きで趣味が合う友人から聞いたのか、普段あまり映画を観ない友人から聞いたのかで、「本当に自分にとって面白い映画なのか」の見積もりが変わりますよね。
「誰が言ったか」という情報が加わることで、自分の中の確率が更新されているわけです。
この自然なプロセスを数学的に定式化したものがベイズ推論なんですね。
プロンプト=事前情報を与える行為
この視点で生成AIを見ると、プロンプトの役割がくっきり見えてきます。
生成AIは、次に来る単語の確率分布を予測して、その中からサンプリングして出力を作っています。
つまり、「この単語の次にはどの単語が来そうか」を確率的に判断しながら、一語ずつ文章を組み立てています。
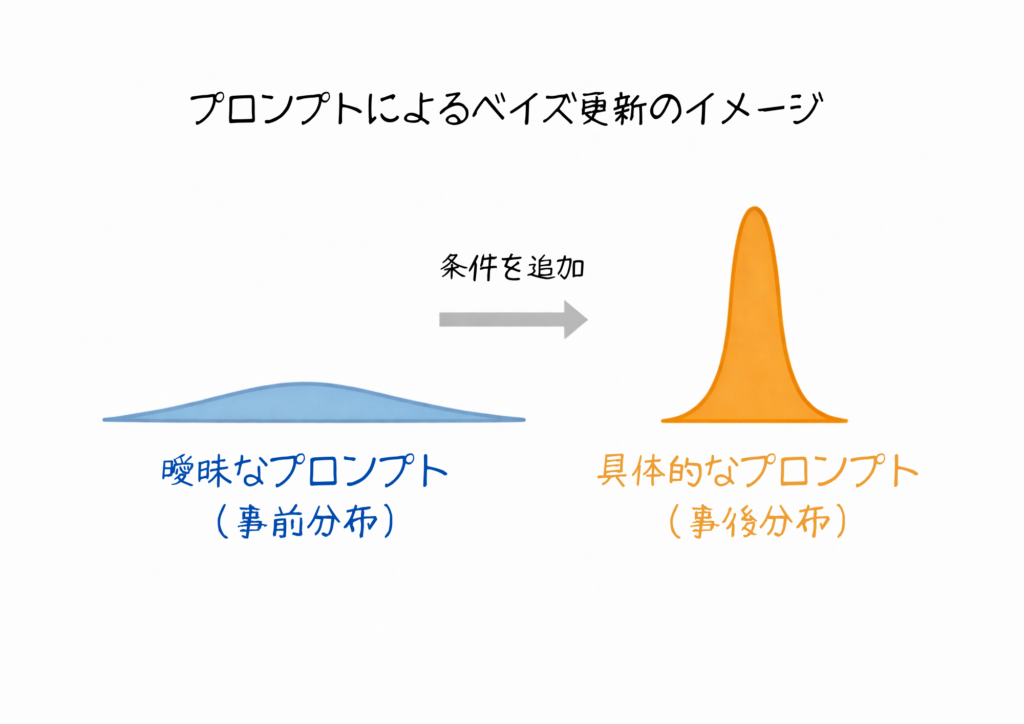
曖昧なプロンプトだと、次に選ぶ単語の候補が多すぎて「ほぼ何を答えてもいい」状態になっている。
どの方向に進んでもそれなりにもっともらしい、という状態です。
これが、曖昧なプロンプトに対して毎回少しずつ違う答えが返ってくる理由でもあります。
選択肢が多すぎるから、サンプリングのたびに違うものが選ばれてしまうんですね。
ここで、プロンプトに条件を加えると、ベイズ推論的に言えば「事前情報が追加されて、確率分布が絞り込まれる」ということが起こります。
たとえば「料理を教えて」だと、和食・洋食・中華・料理の歴史・料理道具の選び方……どの選択肢を選んでもそれなりにもっともらしいので、あらゆる方向に確率が散らばっています。
でも「初心者向けの、30分以内で作れる簡単なパスタのレシピを教えて」と伝えると、「初心者向け」「30分以内」「簡単」「パスタ」「レシピ」という条件が加わって、選択肢がぎゅっと狭まる。
この「選択肢の幅( = 確率分布で)」を少なくすることで、結果として期待に近い答えが返ってきやすくなります。
条件を一つ追加するたびに、AIの出力候補が絞り込まれていくわけですね。
つまり、プロンプトの工夫って「コツ」じゃなくて「確率空間の誘導」だったと言うわけです。
 ゆるめと
ゆるめとこの感覚がつかめると、プロンプト設計の考え方がガラッと変わります。
「コツの暗記」から「情報量のデザイン」へ
この見方が入ると、バラバラに見えていたテクニックが一つの原理でつながります。
「なぜ効くのか」が見えてくると、応用の幅がぐっと広がるんですね。
出力形式の指定
「AIについて説明して」 → 「AIについて、箇条書きで3つのポイントにまとめて説明して」
形式を指定するだけで、出力の候補が大幅に絞られます。
「箇条書き」「3つ」という条件が加わることで、AIは「長い段落で延々と説明する」という選択肢を自然に排除して、コンパクトにまとめる方向に確率が集中します。
形式を指定するということは、AIの出力空間を物理的に制限しているとも言えるんですね。
役割の設定
「この契約書をチェックして」 → 「あなたは法務の専門家です。リスクのある条項を3つ挙げて」
役割を設定すると、AIの確率分布が「その専門家が書きそうな答え」に誘導されると考えられます。
「法務の専門家」と伝えた瞬間に、日常会話的な言い回しより専門的な分析が選ばれやすくなり、「リスクのある条項」というフレームで情報が整理されるようになるんですね。
これは面白い現象で、同じ契約書を見せても「マーケティング担当」と「法務の専門家」では、AIが注目するポイントが大きく変わります。
役割の設定が、確率分布の重心をどこに置くかを決めているというわけです。
Few-shot学習(例示)
例をいくつか示してからタスクを指示する手法も、同じ原理で理解できます。
- りんご → 果物
- にんじん → 野菜
- 鮭 → 魚
- トマト → 「???」
たとえば、上記のようにと3つの例を示してから「トマトは?」と聞くと、AIは「分類タスクをやっている」と高い確率で判断して、「野菜」と返しやすくなります。
もし例を示さずに「トマトは?」とだけ聞いたら、「赤い野菜です」「イタリア料理でよく使います」「リコピンが豊富です」と、何を答えるべきか確率が散らばってしまいます。
例を見せることで「カテゴリ名を答えればいいんだな」と方向が定まるんですね。
ベイズ的に見れば、例という追加の事前情報を与えて、事後確率を更新していると捉えられます。
Chain-of-Thought(段階的思考)
「ステップ・バイ・ステップで考えてください」
と言う指示を追加する「チェイン・オブ・ソート」というプロンプト手法が知られていますが、これも、各ステップが新しい条件として機能して、確率分布が段階的に更新されていくと解釈できます。
たとえば「リンゴが3個、ミカンが5個あります。リンゴを2個食べたら残りは全部で何個?」という問題を考えてみます。
いきなり最終回答を出そうとするより
- 「まずリンゴの残り数を出して」→「3 – 2 = 1個」
- 「次にミカンの数を確認して」→「5個」
- 「合計は?」→「1 + 5 = 6個」
と一段階ずつ進めると、各ステップの出力が次のステップの事前情報になって、最終的な答えの精度が上がるんですね。
これはベイズ推論の逐次的な確率更新と同じ構造です。
一度に大きく更新するのではなく、小さな情報を順番に加えていくことで、確率分布を精密に絞り込んでいくわけです。
共通する原理
どのテクニックも、やっていることは同じ「AIの確率分布に情報を加えて、望ましい方向に絞り込んでいる」ということなんですね。
情報理論の創始者クロード・シャノンは、情報量を「不確実性の減少量」として定義しました。
この視点で見ると、プロンプトが持つ情報量が多いほど、AIの不確実性が減って精度が上がる傾向にあるということになります。
逆に言えば、「何か教えて」のような情報量の少ないプロンプトでは、AIにとって不確実性が高いまま。
だから答えがブレやすいんですね。
プロンプトの良し悪しは、結局のところ、そこに含まれる情報量の多さで決まると考えられます。
逆に、曖昧なプロンプトがうまくいかない理由
ここまでの話を裏返すと、「曖昧なプロンプトがなぜダメなのか」も自然に見えてきます。
曖昧なプロンプトでは、AIが選びうる答えの候補が膨大で、確率が広く分散しています。
どれを選んでも大差ない状態なので、サンプリングのたびに結果がブレるんですね。
同じ質問をしても毎回違う答えが返ってくるのは、確率分布が平坦すぎる、つまり次の単語の選択肢が多すぎるからだと考えられるわけです。
そしてもうひとつ。
ユーザーの側には「こういう答えが欲しい」という明確な期待があるのに、その期待を確率分布の中に反映できていない。結果として「なんか違うな」という感覚が残ってしまう。
期待と出力のミスマッチは、多くの場合、情報量の不足から来ているんですね。
つまり、AIの回答に不満を感じたとき、問題は「AIが賢くない」のではなく、「自分の期待を確率分布に十分に反映できていなかった」という可能性があるわけです。
プロンプトとの付き合い方が変わる
この視点を持つと、プロンプトを書くときの意識が変わります。
「このテクニック、効くのかな?」ではなく
- このプロンプトは、十分な情報量を持っているだろうか?
- AIの確率分布を、望ましい方向に絞り込めているだろうか?
- 曖昧な表現を、もっと具体的にできないだろうか?
思ったような回答が返ってこなかったときも、「テンプレートが悪かったのかな」と探し回る代わりに、
「自分が与えた条件は、AIの確率分布をどの方向に絞り込んでいたんだろう?」
と振り返ることができます。
- 対象読者を指定し忘れていた
- 出力の長さを伝えていなかった
- 背景情報を省略していた
足りなかった条件に気づいて、一つ加えるだけで劇的に結果が変わることもあるんですね。
それは魔法でもコツでもなく、確率分布を適切な方向に誘導できたということなんです。
逆に、条件を増やしすぎて答えが窮屈になるケースもあります。そんなときは
- 条件が互いに矛盾していないか
- 絞り込みすぎて候補が狭くなりすぎていないか
を振り返ると、バランスが見えてきます。
プロンプトは「絞る」だけでなく「適切な幅を残す」ことも大切だったりもします。
コツを覚えるのではなく、「自分が今、AIにどんな確率空間を作らせようとしているか」を意識する。
数学の視点をひとつ持つと、そんな付き合い方ができるようになるのではないでしょうか。
まとめ:数学の視点が入ると、AIが「確率的な装置」として見えてくる
ベイズ推論という視点を一つ入れるだけで、プロンプトエンジニアリングの見え方が変わります。
バラバラに見えていたテクニックが、一本の線でつながるんですね。
- プロンプトは事前分布を狭める操作
- 条件を増やすほど情報量が増え、不確実性が減る
- 結果として望ましい出力の確率が高まる傾向にある
「なぜこのテクニックが効くのか」がわかると、新しい場面でも自分の頭で考えてプロンプトを設計できるようになります。
レシピを暗記する料理人から、食材の性質を理解している料理人へ … そんな変化に近いのかもしれません。
テンプレートが通用しない場面に出会ったとき、原理を知っている人は「じゃあ、どんな条件を足せば確率分布が絞れるだろう?」と考えることができます。
ChatGPTでもClaudeでもGeminiでも、確率的に出力を生成しているという構造は同じ。
だからこの視点は、特定のツールに依存しない、根っこの部分の理解になるんですね。
生成AIを「魔法の箱」ではなく、確率的に動く装置として見る。
そう見えた瞬間から、プロンプトは「呪文」ではなく「設計」に変わります。
その視点の転換の手がかりが、ベイズ推論という数学の中にあったんですね。
関連する数学分野: ベイズ統計学、確率論、情報理論(シャノンの情報量)