「たしかに近いけど違う」が出てくる
おすすめ欄を見ていて、「たしかに近いけど、そうじゃないんだよな」と思うことないですか?
一度見た動画に似た動画が並ぶ。 買った商品に似た商品が出る。 検索した言葉に近い記事が出る。 方向性は外していないのに、いちばん欲しいものからは少しズレている。
AIはクリック履歴や閲覧時間などを手がかりにして候補を選ぶわけですが、ここで一つ不思議があります。
なぜ「ぜんぜん違う」ではなく、「近いけど違う」がこんなに多いのでしょうか。
近さは一種類ではない
このズレを、線形代数の見方で解釈できるか試してみます。
線形代数は、ざっくり言えば「いくつもの数字をまとめて、向きや距離として扱う数学」です。 商品、動画、記事、ユーザーの好みを、いくつもの特徴を持った点として置いてみる。 そうすると、おすすめは「この人の点に近い候補を探す作業」として読めます。
ただし、ここでいう「近い」は一種類ではありません。
価格が近い。 ジャンルが近い。 雰囲気が近い。 直前に見たものに近い。 過去に長く見ていたものに近い。
どの近さを強く見るかで、出てくる候補は変わります。 「たしかに近いけど違う」は、AIが外したというより、AIが見ている近さと、今ほしい近さが少し違うときに起きる現象として読めます。
好みを地図に置いてみる
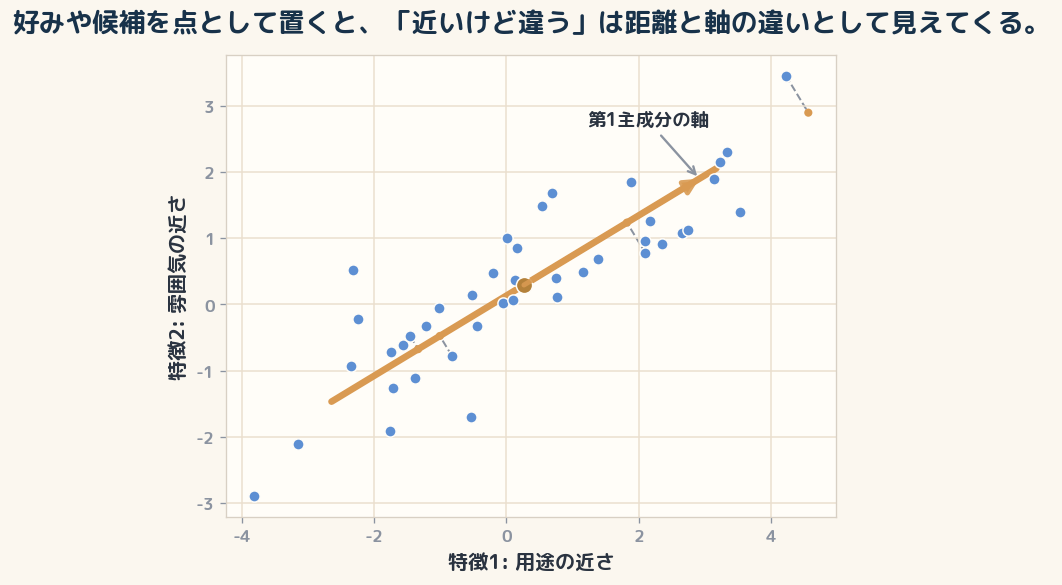
小さな模型として考えてみます。 実際の推薦システムがそのままこの少数の特徴だけで動いている、という話ではありません。 現実にはもっと多くの特徴、履歴、ランキングモデルが絡みます。 それでも、点と距離の模型にすると「近いけど違う」が見えやすくなります。
たとえば、ある記事を次のような点として置きます。
– 仕事で使う度合い – 軽く読める度合い – 専門性の高さ – 最近の関心との近さ
この4つを数字にすれば、記事は4つの数字を持つ点になります。 ユーザーの今の好みも、同じ4つの数字を持つ点として置けます。
ここでAIが「近い」と判断した記事は、4つの数字のどこかではたしかに近い。 でも、読んでいる側が今日は「仕事で使えるか」を一番見ているのに、AIが「軽く読めるか」を強く見ていたら、候補はズレます。
同じ「近い」でも、見ている軸が違うからです。
検索でも同じことが起きる
この見方は、おすすめ欄だけに限りません。
検索で「それっぽいけど求めていた記事ではない」結果が出るときも、同じことが起きています。 文面は近い。 テーマも近い。 でも、用途が違う。
AIに資料作成を頼む場面でも似ています。 「初心者向けで」と頼むと、文章はやわらかくなる。 しかし、読み手が社内の意思決定者なのか、新人研修の参加者なのかで、近い資料は変わります。
AIが選ぶ候補は、こちらが渡した言葉から作った地図の上で近いものです。 地図の軸が足りなければ、近い候補の中に「そうじゃない」が混ざります。
数式で見てみると
この「近さ」を式に書き直してみます。
候補を $x$、今の好みを $p$ とします。 $x$ も $p$ も、いくつもの特徴を並べたベクトルです。 ベクトルは「数字のリスト」だと思えば十分です。
特徴が $m$ 個あるとき、近さのズレはたとえば次の距離で見られます。
これは、重み付きのユークリッド距離と呼ばれる形です。 近さの測り方はこれだけではありません。 文章や画像を数字のリストにしたあと、向きの近さを見るコサイン類似度や、向きと大きさをまとめて見る内積が使われることもあります。 この記事では、「近さにも設計がある」ことを見るために、距離の形で書いています。
$p_j$ は「今の好み」の $j$ 番目の特徴です。 $x_j$ は「候補」の $j$ 番目の特徴です。 $p_j – x_j$ は、その特徴だけを見たときのズレです。
$w_j$ は、その特徴をどれくらい重く見るかを表す0以上の数字です。 $w_j$ が大きい特徴は、少しズレただけでも全体の距離に強く効きます。 逆に $w_j$ が小さい特徴は、ズレていてもあまり問題にされません。
実務では、この重みを人が毎回手で決めるとは限りません。 クリック、購買、滞在時間などのデータから、ランキングモデルが効きやすい特徴の組み合わせを学ぶ場合も多いです。
つまり、おすすめ欄の「近い」は、ただの近さではありません。 どの特徴を強く見るかまで含んだ近さです。
もしAIが「ジャンル」を重く見て、「用途」を軽く見ていたら、ジャンルは近いけれど用途は違う候補が出ます。 もしAIが「直前に見たもの」を重く見すぎていたら、一度クリックしただけの方向に候補が寄ります。
「近いけど違う」は、この重みの置き方が見えてしまった瞬間として読めます。
ただし、このズレの原因が距離設計だけだという話ではありません。 情報が少ない新商品や新規ユーザーでは、そもそも手がかりが足りないコールドスタートが起きます。 人気のある候補を優先する人気バイアスもあります。 いつもの好みに寄せるか、新しい候補を試すかという探索と活用のバランスも効きます。 この記事では、その中の一つとして「近さの測り方」を見ています。
「近い」の意味を指定し直す
おすすめがズレたとき、「精度が悪い」で終わらせることもできます。 でも、点と距離の見方を入れると、次の問いに変わります。
AIは、どの軸で近いものを選んでいるのか。 今ほしい候補には、どの軸が足りないのか。 どの条件を重く見てほしいのか。
検索語やプロンプトに「用途」「除外したい方向」「譲れない条件」を足すのは、単なるお願いではありません。 AIに渡す地図に、新しい軸や条件の手がかりを足す操作として見られます。
「近いけど違う」と感じた瞬間は、AIの選び方を調整する入口かもしれません。 近いものを出してもらうだけでなく、「どの意味で近いのか」まで指定できたら、おすすめ欄や検索結果はこちら側から少し動かせるかもしれませんね。