文章を入れるだけで絵が出てくる、あれ不思議じゃないですか?
画像生成AIに「夕暮れの海辺を歩く猫」とだけ打ち込むと、見たこともない絵がちゃんと出てきます。 便利で毎日使っているけれど、ふとした瞬間に「そもそも、言葉がどうやって絵に変わってるんだろう?」と不思議に思うことないですか?
「学習した絵を真似してる」の、その先
たくさんの画像を学習しているから、それっぽい絵を作れるわけですが、本当に面白いのはその先です。 学習した絵をそのまま貼り合わせているなら、「見たこともない猫」がなぜ出てくるのか説明がつきません。 ここで一つ不思議が残ります。 言葉という文字の並びと、絵というピクセルの集まりは、まったく違うものに見えます。 その二つが、どうやって結びついているのでしょうか。
言葉も絵も、同じ「広い空間の中の位置」だとしたら
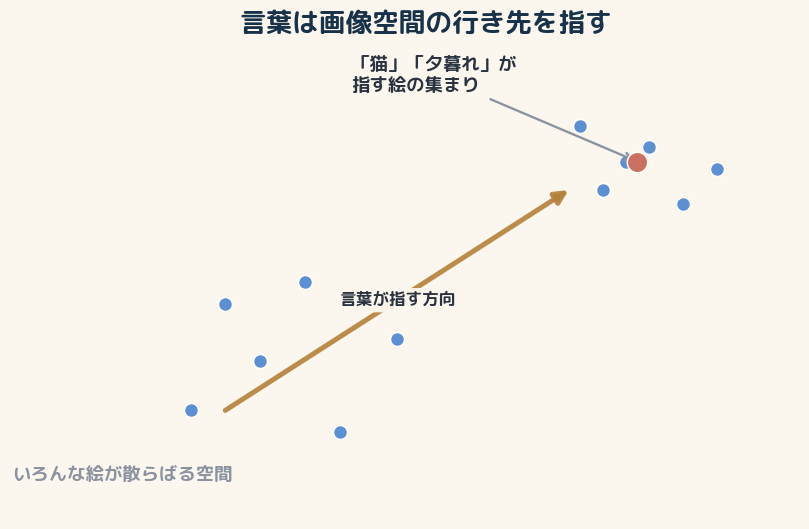
実は数学です、と言いたくなりますが、ここは線形代数の目で解釈できるか、やってみましょう。 画像生成AIの中では、一枚の絵が「とても多くの数字の並び」、つまり高次元空間の中の一点として扱われています。 どれくらい多いのか、ためしに数えてみます。一辺512ピクセル、赤・緑・青の3枚ぶんある絵なら、512×512×3でおよそ78万個の数字。つまり一枚の絵は、78万本の軸を持つ空間のたった一点なんです。 私たちが「猫っぽい」と感じる手がかりも、その78万個のどこかに散らばって埋まっています。AIはこの気の遠くなる座標を、「猫らしさ」「夕暮れらしさ」ごとにいい感じに圧縮して整頓した、扱いやすい座標系へと学び直している。高次元空間というのは雰囲気を出すための比喩ではなく、必要があって出てきた線形代数の道具なんですね。 似た絵どうしは近くに、まったく違う絵どうしは遠くに配置される、そんな広い地図を思い浮かべてください。 言葉はその地図と対応づけられ、「こっちの方向だよ」と画像側の行き先を指す矢印のように働きます。 面白いのは、その言葉もまずは数字の並びに置き換えられている、という点です。言葉が数字になるからこそ、絵と同じ土俵にのせて「方向」として扱えるわけですね。 「猫」という言葉は猫らしい絵が集まっている方向を、「夕暮れ」はその色合いが強まる方向を指す。 言葉は絵そのものではなく、地図上の進む向きを決める道しるべなんですね。 だから言葉を足すたびに、行き先の矢印が少しずつ向きを変えていきます。 「見たこともない猫」が出てくるのも、地図の中のまだ見ぬ地点へ、矢印の組み合わせで近づいているからだと考えると、すっきりします。
ちなみに、この「高次元空間の近さ」という同じ見方は、AIのおすすめがなぜ「近いけど違う」候補を出すのかにも顔を出します。
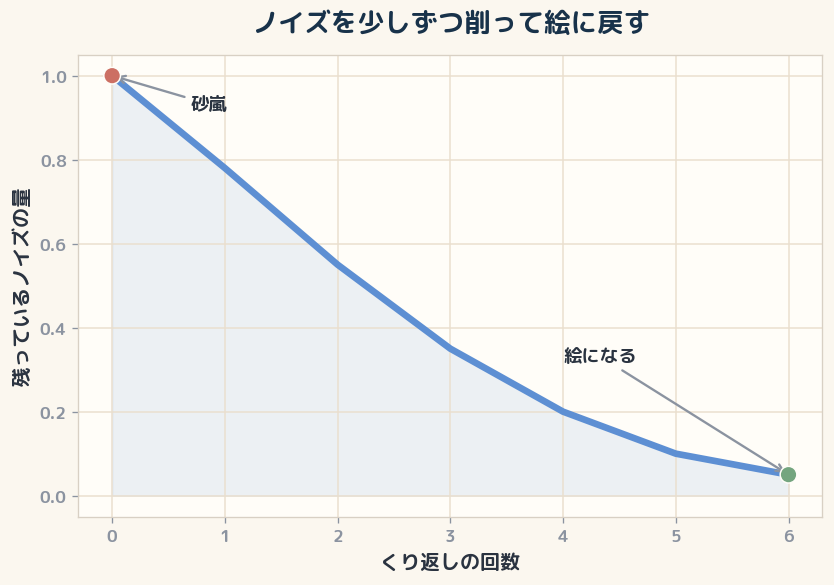
砂嵐から絵を彫り出す
面白いのは、AIがこの地図の上で絵を「最初から描く」のではなく、「砂嵐から彫り出す」ように作る点です。 まずランダムなノイズ、つまり意味のない砂嵐の画像から始めます。 そこから「この砂嵐のうち、余計なざらつきはどれくらいか」を少しずつ見積もって取り除いていきます。 これを何十回も繰り返すと、ノイズの中からだんだん絵が浮かび上がってきます。 彫刻家が石の塊から余分を削って像を出すのに少し似ています。 そして、どの方向に削るかを決めているのが、さっきの言葉の矢印です。 ここでプロンプトの一語差が効いてきます。 「猫」だけなら猫らしい方向へ進みますが、「水彩の猫」と書けば、同じ猫でも色のにじみや輪郭のやわらかさが出やすい方向へ寄ります。 「写真のような猫」と書けば、今度は質感や光の入り方が写真的な方向へ寄ります。 どちらも猫を指定しているのに仕上がりが変わるのは、言葉が絵の部品を足しているからではなく、削る方向を変えているからだと読めます。
式で見ると、引き算をくり返しているだけ
この「少しずつ削る」を式に書き直してみると、こう読めます。
記号に身構えなくて大丈夫です。一つずつ日常語に戻します。 $x_t$ は「いま途中まで仕上がっている絵」です。最初は砂嵐で、進むほど絵に近づきます。 $\varepsilon_\theta(x_t, c)$ は「AIが余計なノイズだと見積もった分」です。 $a_t$ は、その回でどれくらい削るかを決める小さなつまみです。 そして $c$ が、入力した言葉です。これが「どの方向のノイズを削るか」を毎回そっと方向づけしています。 本物の式には、さらに細かい係数や乱数を足す処理も入ります。 ただ、骨組みは「いまの絵から、見積もったノイズを少し引く」のくり返しだと思って大丈夫です。 細かい重みを外して眺めると、やっていることの素直さが見えてきます。
ためしに極端な場合を考えてみましょう。 もし言葉 $c$ が空っぽなら、「猫」や「夕暮れ」のような条件づけは弱くなり、モデルが持っている画像らしさのほうに任せる部分が大きくなります。 逆に $c$ で条件を具体的にすると、毎ステップの削り方が「猫らしさ」「夕暮れらしさ」へ寄りやすくなります。 言葉は絵を直接描くのではなく、この引き算のたびに行き先を少しずつ絞り込んでいる、と見ると腑に落ちます。 ごく単純な1次元の世界で動かしてみると、もっとはっきりします。本当の絵が数直線の0.3あたりにあるとして、いまの位置が0.9だとします。毎回「行きすぎているぶん」を少しだけ引くと、0.9→0.6→0.4→0.3…と、削るたびに本当の場所へにじり寄っていく。式で書くのは、この「ちょっとずつ近づける」作業を、何十回ぶんも迷わず正確に指示するためなんですね。
持ち帰り
そう考えると、プロンプトに足す一語は、絵の上に色を置く筆ではなく、削る方向を変える舵だったわけです。 「猫」に「ふわふわの」を足すと結果がガラッと変わるのは、行き先の矢印が別の方を向くからなんですね。 だとしたら、言葉の選び方ひとつで高次元空間の行き先を思ったより動かせる、ということになります。 高次元空間での距離や方向をきちんと計算できるからこそ、AIは「見たこともない猫」にもまっすぐ矢印を向けられる。これが、数学があるからこそできるようになった画像生成の正体の一つです。 次に何か一語を足すとき、自分がその広い地図のどこを指そうとしているのか、ちょっと覗いてみたくなりませんか?