フック
同じようにChatGPTへ話しかけているのに、ある日はやけに冷たく、別の日はやけに親切に返ってくることないですか?
昨日は「了解です。以下です。」くらいで終わったのに、今日は理由まで添えて妙に寄り添ってくる。 頼み方を大きく変えたつもりはないのに、返事の温度だけが少し違う。
これ、AIに気分があるという話ではありません。 でも、ただの気まぐれとして流すには、けっこう面白い揺れです。
同じ質問なのに、なぜ口調まで揺れるのか
AIは入力に合いそうな言葉を順に選んで文章を作っているわけですが、ここで一つ不思議があります。
同じ質問なら、同じ答えに近づきそうです。 内容が多少変わるのはまだわかります。 でも「冷たい」「親切」「事務的」「やわらかい」まで変わるのは、どこで決まっているのでしょうか。
ここでは、返事を一つの正解としてではなく、あり得る返事の候補が並んだ分布として捉えてみます。 もちろん実際の揺れは、プロンプトだけでなく、会話履歴、モデルやシステムの更新、プロバイダ側の内部設定にも影響されます。
返事の温度は、候補の広がりとして読める
たとえば「会議の議事録を要約して」と頼んだとします。 候補は一つではありません。 短く箇条書きにする返事もあれば、背景を補って丁寧に説明する返事もあります。 少し断定的な返事も、慎重な返事も、文脈によってはどれも「あり得る」候補です。
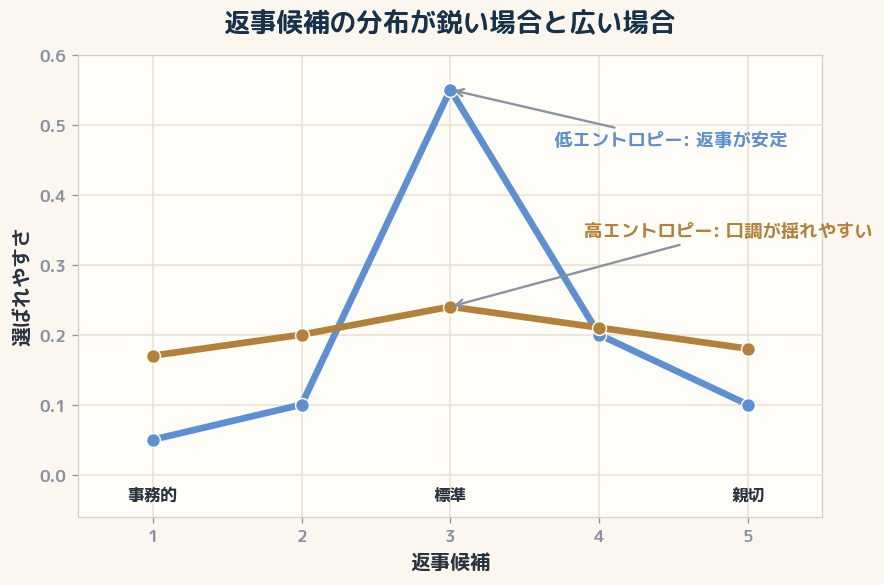
このとき、AIは候補の中から一つを選びます。 一番それらしい候補が圧倒的に強ければ、返事は安定します。 逆に、同じくらいあり得る候補がいくつも並ぶと、選ばれる言い回しが揺れます。 ここでいう候補は、文章全体を丸ごと先に並べているという意味ではなく、次に出す語や表現の選ばれやすさを、読みやすい形にまとめたものです。
「今日は冷たい」「今日は親切」と感じる差は、候補の中でどのトーンが選ばれやすくなっているかの差として解釈できます。 文末の一語、前の会話、依頼の粒度に加えて、モデル更新や安全設定の変更のようなシステム側の変化も、その分布を少しだけ動かす可能性があります。 だから「昨日と今日で返答のトーンが違う」と感じるとき、こちらの聞き方だけでなく、バックエンド側の更新が理由に混ざっていることもあります。
無難な返事にも同じ仕組みが顔を出す
この見方をすると、口調だけでなく、AIの返事が「無難すぎる」と感じる現象も近いものとして捉えられます。 強い候補が安全な言い回しに偏ると、毎回きれいだけど踏み込まない返事になりやすいからです。
返事が無難に寄る話は、こちらの記事でも情報量の見方で扱っています。
親切さ、冷たさ、無難さは、別々の性格ではありません。 候補の分布がどちらへ寄っているかの違いとして読めます。
数式に直してみる
返事の候補を $r_1, r_2, \dots, r_n$ と置きます。 $r_i$ は「候補 i の返事」です。 たとえば、$r_1$ は事務的な返事、$r_2$ は丁寧な返事、$r_3$ はかなり親切な返事、という具合です。 これは説明のために、返事全体を候補としてまとめた小さなモデルです。 実際のLLMは、文章全体を先に並べて一つ選ぶのではなく、各時点で次のトークンの分布 $p(x_t \mid x_{<t}, \text{prompt})$ を作り、そこから一つずつ選んでいきます。 事務的・親切といった口調は、そのトークン単位の選択が積み重なった結果として現れます。
それぞれの候補が選ばれる確率を $p_i$ とすると、候補の広がりはエントロピーで見られます。
$H(p)$ は「候補の選ばれ方がどれくらい散らばっているか」です。 一つの候補だけがほぼ選ばれるなら、$H(p)$ は小さくなります。 いくつもの候補が同じくらい選ばれるなら、$H(p)$ は大きくなります。
もう一段だけ、選び方の式も見てみます。 候補 $r_i$ にスコア $z_i$ があるとして、温度 $T$ を入れると、確率は次の形で表せます。
$z_i$ は「その候補が文脈にどれくらい合っているか」の点数です。 $T>0$ は分布を鋭くしたり、ゆるめたりするつまみです。 $T$ が小さいと、点数の高い候補に寄ります。 $T$ が大きいと、候補の差がならされ、少し違う返事も出やすくなります。 APIではtemperatureやtop-pのような設定で、この揺れ幅をある程度調整できる場合があります。 ただし、サービスによってはユーザーに見えない内部設定、モデルのルーティング、安全側の補正も入ります。 つまり「どのくらい揺れるか」は、ユーザー側のつまみだけでなく、プロバイダ側の設計にも左右されます。
実際のChatGPTの内部設定や生成過程を、この式だけで説明できるという意味ではありません。 ここでの $r_i$ や $p_i(T)$ は、トークン単位の複雑な分布操作を、返事のトーンという読者に見える単位へ粗く写したモデルです。 ただ、返事が固定の一個ではなく、候補分布から選ばれていると考えると、口調の揺れはかなり扱いやすくなります。
持ち帰り
ChatGPTの返事が冷たく感じたとき、それを機嫌の問題として読むと、こちらは待つしかありません。
でも、候補の分布として読むと、できることが変わります。 「少しくだけて」「結論は先に」「理由は一文だけ」「相手に送る文面として」といった指定は、返事の候補を別の場所へ寄せる操作になります。
AIの口調を当てに行くのではなく、出てきやすい返事の分布を設計する。 そう考えるだけで、ChatGPTとの会話は、相手の気分を読む作業ではなく、出力の形を調整する作業に変えられるかもしれませんね。