
「90%オフ」と「正解率90%」、なぜ印象が違うんだろう
スーパーで「90%オフ」って書いてあったら、すごくお得に感じますよね。
でも、お医者さんに「この病気の診断、正解率90%です」って言われたら、ちょっと不安になりませんか?
同じ「90%」なのに、受け取る印象がまったく違う。
この違和感、実はすごく大事なんです。
最近、AIサービスのサイトでよく見かける「精度90%以上!」という表記。
一見すごそうに見えるけど、実際に使ってみると「あれ?」って思うこと、ありませんか?
文章を要約してもらったら大事なところが抜けてたり、質問に答えてもらったら微妙に違う情報が混ざってたり。
「90%って高いはずなのに、なんで?」
今回はその理由を、数学の視点も使いながら見てみたいと思います。
AIの「精度」って、何の精度なんだろう
「精度」だけじゃ、実は何も分からない
「このAI、精度90%です」って言われても、実は情報が足りてないんですよね。
まず「精度(Accuracy)」っていうのは、AIが出した答えのうち、どれくらいが正解だったかを示す数字のこと。
でも、これだけじゃ実は何も分からないんです。
例えば、料理のレシピサイトで「成功率90%」って書いてあったとします。
でも、それって何の成功率なんでしょう?
初心者が作っても90%?
プロが作ったら90%?
見た目が綺麗にできる確率?
それとも味が美味しくなる確率?
AIの精度も同じなんです。
OpenAIが公開しているGPT-4の評価データによると、タスクによって性能が大きく変わることが報告されています。
文章生成や画像の説明は高精度な一方で、数学の問題では正答率が大きく下がるとされています(OpenAI公式ブログ、2023年)。
同じAIなのに、やることによって全然違う。
10回に1回間違えるという意味
「精度90%」を別の言い方にすると「10回のうち1回は間違える」ってことですよね。
でも、この1回の間違いの「重さ」って、場面によって全然違いませんか?
例えば、メールの下書きを作ってもらうとき。
10通のうち1通が微妙な表現でも、自分で直せば済みます。
これは「許せる1回」。
でも、医療の診断で10人に1人が誤診だったら?
お金の計算で10回に1回ミスがあったら?
これは「許せない1回」ですよね。
数学的に言うと、これは「期待損失」の考え方に近いんです。
平均的には90%正解でも、その10%の誤りがどこに現れるか、そして1回の誤りがどれだけの損失をもたらすかで、リスクの大きさがまったく変わってくる。
確率論では、こういうとき「誤りの重み」を考えます。式で書くと、
期待損失 = 誤り率 × 1回あたりの損失
って感じなんですね。
同じ10%でも、掛け算する「損失」が大きければ、全体のリスクは跳ね上がる。
だから「精度90%」だけ聞いて安心しちゃいけないんです。
精度だけじゃ分からない「間違え方の中身」
混同行列で見えてくる、4つの結果
「精度90%」って聞くと、なんとなく「ほとんど正解してる」って思いますよね。
でも、実はどう間違えているかが分からないと、その数字はあまり意味がないんです。
ここで役立つのが「混同行列(Confusion Matrix)」っていう考え方。
AIが何かを判定するとき、結果は実は4種類に分かれるんです。
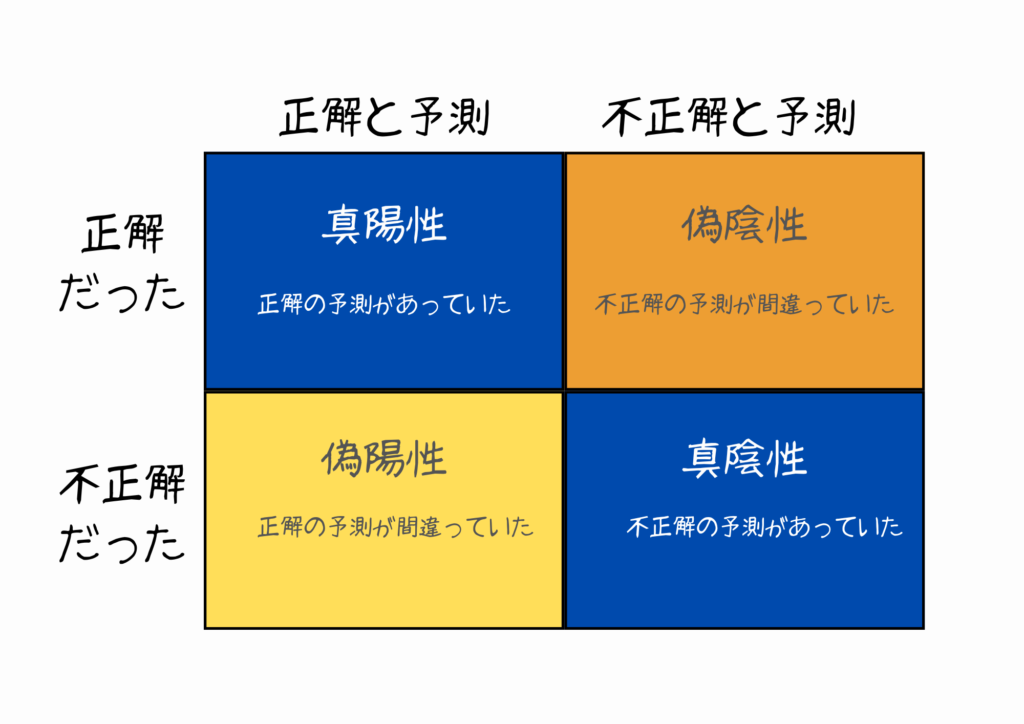
- 真陽性(True Positive):「病気です」と言って、実際に病気だった
- 真陰性(True Negative):「病気じゃないです」と言って、実際に健康だった
- 偽陽性(False Positive):「病気です」と言ったけど、実際は健康だった(空振り)
- 偽陰性(False Negative):「病気じゃないです」と言ったけど、実際は病気だった(見逃し)
この4つを表にしたのが混同行列なんですね。
「空振り」と「見逃し」、どっちが怖い?
ここで大事なのが、偽陽性(空振り)と偽陰性(見逃し)は、重さが全然違うってことなんです。
例えば、がんの診断AIを考えてみましょう。
偽陽性(空振り):健康なのに「がんの疑いあり」と判定
→ 精密検査を受けることになるけど、結果的に健康だと分かる。不安にはなるけど、命には関わらない。偽陰性(見逃し):がんなのに「健康です」と判定
→ 治療が遅れて、命に関わるかもしれない。
同じ「間違い」でも、重さが全然違いますよね。
スパムフィルタだと、また違います。
偽陽性(空振り):大事なメールをスパムと判定
→ 重要な連絡を見逃すかもしれない。これは困る。偽陰性(見逃し):スパムを普通のメールと判定
→ ちょっと迷惑だけど、削除すればいいだけ。
医療とは逆で、偽陽性の方が困るケースなんですね。
「精度90%」でも使い物にならないケース
ここで、具体例を見てみましょう。
ある病気のスクリーニングAIがあって、「精度90%」って言われたとします。
でも、実際のデータを混同行列で見てみると…
実際に病気 実際に健康
AIが陽性 10人 90人
AIが陰性 0人 900人
これ、計算すると確かに精度90%なんです。
精度 = (真陽性 + 真陰性) / 全体 = (10 + 900) / 1000 = 91%
でも、「病気です」って言われた100人のうち、本当に病気なのは10人だけ。
残りの90人は健康なのに、不安になって精密検査を受けることになる。
これ、実際に使えるAIでしょうか?
病気の人は全員見つけられてる(偽陰性ゼロ)から、その点は良いんです。
でも、健康な人の10%(90人)を「病気かも」って言っちゃってる。
これだと、医療現場が混乱しちゃいますよね。
逆のパターンもあります。
実際に病気 実際に健康
AIが陽性 8人 2人
AIが陰性 2人 988人
これも精度は約90%です。
精度 = (8 + 988) / 1000 = 99.6%
でも、病気の人10人のうち2人を「健康です」って言っちゃってる(偽陰性)。
この2人は治療が遅れるかもしれない。
同じ「精度90%」でも、中身が全然違うんです。
精度以外の指標が必要な理由
だから、医療AIの評価では「精度」だけじゃなくて、こんな指標も使われるんです。
適合率(Precision):「病気です」と言ったうち、本当に病気だった割合
→ 空振りの少なさを測る再現率(Recall):実際の病気のうち、ちゃんと見つけられた割合
→ 見逃しの少なさを測る
式で書くと、次のような感じです。
適合率 = 真陽性 / (真陽性 + 偽陽性)再現率 = 真陽性 / (真陽性 + 偽陰性)
最初の例だと、適合率は10%(10/100)で、再現率は100%(10/10)。
2番目の例だと、適合率は80%(8/10)で、再現率は80%(8/10)。
どっちのバランスを重視するかは、使う場面によって変わる。
医療なら見逃しを減らしたいから再現率重視、スパムフィルタなら空振りを減らしたいから適合率重視、というわけです。
AIの間違え方は、人間と全然違う
人間は「疲れて」間違える、AIは「確率的に」間違える
人間が間違えるときって、だいたい理由がありますよね。
疲れてた、集中できてなかった、そもそも知らなかった。
だから「分からない」って言えるし、「自信ない」って伝えられる。
でも、AIは違いますよね。
AIは「確率的に言葉を選んでいる」だけなので、疲れることはありません。
その代わり、「分からない」と言えないんです。
どんなに精度の高いAIでも、一定の確率で「幻覚(ハルシネーション)」と呼ばれる現象が起きることは、今や周知の事実です。
ハルシネーションとは、AIが「もっともらしいが間違った情報」を自信を持って出力してしまうことです。
例えば、存在しない論文を引用したり、実在しない統計データを出したり。
人間なら「ちょっと調べてから答えます」って言えるけど、AIにはそれが難しいわけです。
「わからない」と言えないリスク
これ、けっこう怖いことなんです。
人間の専門家なら「これは私の専門外なので、詳しい人に聞いてください」って言えます。
でもAIは、どんな質問にも何かしら答えを返してくる。
海外メディアでは、チャットボット型AIの医療相談を鵜呑みにした患者が、誤った自己治療や受診の遅れによって救急搬送に至ったケースが複数報告されています(例:New York Post, 2025年10月24日付記事 など)。
AIは「知らない」ことを確率的に低く見積もるけど、ゼロにはしない。
だから必ず何かしらの答えを生成してしまう。
これが、人間の間違いとAIの間違いの、根本的な違いなんです。
数学的に言うと、AIは「確率分布からサンプリングしている」だけ。
だから、低確率でも「ありえない回答」が出てくることがある。
人間なら「ありえない」と判断して止まるところを、AIは止まらないんですね。
「精度90%」の罠〜全体的な性能を測るAUCという指標
精度だけでは見えない「判定能力」
ここまで見てきたように、「精度90%」っていう数字だけじゃ、AIの本当の性能は分からないんです。
偽陽性と偽陰性のバランスも大事だし、どのくらい自信を持って判定してるかも大事。
そこで使われるのが「AUC(Area Under the Curve)」っていう指標です。
AUCは、「全体的な判定能力」を測る指標で、0から1の間の値を取ります。1に近いほど性能が良くて、0.5だと「コイン投げと同じ(ランダム)」って意味になります。
ROC曲線とAUCの関係
AUCを理解するには、「ROC曲線」っていうグラフを知っておくと分かりやすいです。
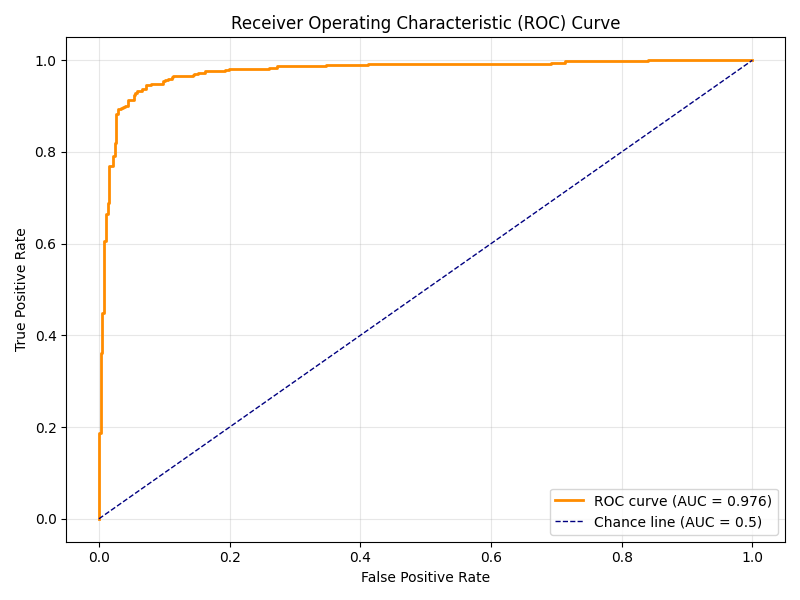
ROC曲線っていうのは、AIの判定の「厳しさ」を変えたときに、真陽性率(見つけられた病気の割合)と偽陽性率(誤って病気と言った割合)がどう変わるかを示したグラフなんです。
例えば、病気の判定AIで考えてみましょう。
- 判定を「厳しく」すると:本当の病気も見逃しやすいけど、誤報は減る(偽陽性↓、偽陰性↑)
- 判定を「甘く」すると:病気は見逃さないけど、誤報が増える(偽陽性↑、偽陰性↓)
このトレードオフの関係を、グラフで表したのがROC曲線なんですね。
そして、このROC曲線の下の面積がAUCなんです。
AUC = 1.0:完璧なAI。病気を全部見つけて、誤報もゼロ。
AUC = 0.9:かなり優秀。医療AIならこのレベルを目指す。
AUC = 0.7:まあまあ。実用には工夫が必要。
AUC = 0.5:コイン投げと同じ。使い物にならない。
AUCが教えてくれること
AUCの良いところは、判定の閾値(しきいち)に依存しないってことなんです。
さっきの混同行列の例だと、「どこで陽性/陰性を区切るか」で結果が変わっちゃいましたよね。
でもAUCは、全体的な判定能力を一つの数字で表してくれる。
だから、複数のAIを比較するときに便利なんです。
- AIモデルA:精度90%、AUC 0.85
- AIモデルB:精度88%、AUC 0.92
この場合、精度だけ見るとAの方が良さそうだけど、AUCで見るとBの方が全体的な判定能力は高い。
Bの方が、偽陽性と偽陰性のバランスが良いってことなんですね。
実際の医療AIの評価では、精度だけでなくAUCも必ず報告されます。
論文を見ると「AUC 0.90以上」みたいな基準が書いてあることが多いんです。
AUCにも限界はある
ただ、AUCも万能じゃないんです。
AUCは「全体的な性能」を測るけど、どんな間違いをしてるかまでは分からない。
だから、混同行列と組み合わせて使うのが大事なんですね。
- AUC:全体的な判定能力を一つの数字で
- 混同行列:どう間違えてるかの詳細を
- 適合率・再現率:空振りと見逃しのバランスを
この3つを組み合わせると、AIの性能が立体的に見えてくる。
「精度90%」って数字だけじゃ分からなかったことが、ちゃんと見えるようになるんです。
タスクによって、AIの得意・不得意は全然違う
文章の要約は得意だけど、事実確認は苦手
実際のところ、AIってタスクによって正解率がまったく違うんです。
ただし、この「誤り」の中身が大事で、日付がずれてたり、重要な情報が抜けてたりすることがあります。
ruthfulQAというベンチマーク(AIの真実性を測るテスト)によると、外部の検証ではGPT‑4でも正答率が約60%程度と報告されています(例:TurnTrout, “Gaming TruthfulQA: Simple Heuristics Exposed Dataset Weaknesses”, 2025年)。
つまり、半分近くは「もっともらしいけど間違った情報」を出してくる可能性がある、というわけですね。
数学や論理は、意外と苦手
「AIって計算得意なんでしょ?」って思いますよね。
でも、実は数学の問題になると、けっこう苦手なんです。
MATHという数学ベンチマークでは、GPT-4の正答率は40〜50%程度という結果が報告されています(arXiv:2103.03874、2021年発表)。
つまり、半分以上は間違える可能性がある。
理由は、途中の論理が崩れやすいから。
人間なら「あれ、おかしいな」って気づくところを、AIは気づかずに進んじゃう。
ただ、「途中式を書いて」ってお願いすると、正解率が上がることが分かってます。
これを「チェイン・オブ・ソート(CoT:思考の連鎖)」って言うんですけど、AIに一歩ずつ考えさせる手法のこと。
GPT-5の Thinking モードなんかは、CoTを内部的に使う推論モードだったりしますね。
AIにとって苦手なタスクでも、段階的に考えさせることで、間違いを減らせるというわけです。
画像認識は高精度、でも1%のミスが命取りになることも
画像認識は、AIが得意な分野の一つです。
ImageNetという有名なベンチマークでは、近年のモデルで正解率80〜90%程度を達成しています(image-net.org、モデルによって異なる)。
でも、医療の現場では話が変わります。
皮膚がんの診断で1%間違えたら、患者さんの命に関わるかもしれない。
「99%正解」でも、その1%がどこに現れるかで、リスクの大きさは全然違うんです。
だから、画像認識AIを使うときは、必ず「信頼度スコア(Confidence)」を確認することが大事。
これは、AIが「この判定にどれくらい自信があるか」を0〜100%で示す数値のこと。
AIが「この判定、80%の自信です」って言ってたら、人間がもう一度確認する。
そういう使い方が必要なんですね。
医療画像診断AIの評価では、精度やAUCだけでなく、混同行列で「見逃し(偽陰性)」がどれくらいあるかを厳しくチェックします。
がんを見逃すのは絶対に避けなければいけないので、再現率を最優先にするんです。
コードは書けるけど、ロジックのミスが潜んでる
プログラミングのコードを書いてくれるAI、便利ですよね。
GitHub Copilot とか、最近では Claude Code なんかがすごく話題だったりしますよね。
でも、成されたコードには、無視できない割合でロジックエラーやセキュリティの脆弱性が含まれることが、複数の研究で報告されています。
例えば、NYUの研究ではGitHub Copilotが生成したコードの約4割に脆弱性が含まれていたとされており、別の実証研究でもPythonコードの約3割にセキュリティ上の弱点が見つかったと報告されています。
「動くコード」と「正しいコード」は、別物なんですね。
だから、AIが書いたコードはそのまま使わずに、必ず人間がレビューする。
これが、実務では常識になってます。
数字に騙されないために〜使い方を変えれば、リスクは減らせる
「高精度」の裏に隠れているもの
人間は「精度90%」って聞くと、すごく高性能という印象を安易に持ってしまいがちです。
でも、ここまで見てきたように、その数字だけじゃ何も分かりません。
- 何のタスクで90%なのか
- どんなデータで測ったのか
- 誤りの10%は、どんな種類の間違いなのか(偽陽性?偽陰性?)
- 全体的な判定能力(AUC)はどうなのか
こういうことが分からないと、「90%」っていう数字は、ほとんど意味がないのです。
ニュース記事の要約で「精度90%」って言われても、その10%が「日付のミス」なのか「事実の誤認」なのかで、リスクは全然違うわけなんです。
確率を「感覚」で捉えない
人間って、確率を感覚で捉えるのが苦手な気がします。
「90%」って聞くと「ほぼ確実」って感じがするけど、実際には「10回に1回は外れる」ってこと。
しかも、その1回がいつ来るかは分からない。
統計学では、これを「確率分布」で考えます。
同じ「10回に1回」でも、どのタイミングで外れるかの「ばらつき」が大事なんです。
試行回数が少ないときは、たまたま連続で外れることもある。
試行回数が増えると、全体としては10%に近づいていく。
式で書くと、
分散 = 確率 × (1 - 確率)
って感じで、確率が0.5(50%)に近いほど、ばらつきが大きくなる。
逆に、90%とか10%とかだと、ばらつきは小さい。
でも、ゼロじゃない。
だから、「たまたま連続で外れる」こともありえるんですね。
「使い方」を変えれば、リスクは減らせる
では、AIは使わない方が良いのでしょうか?
そうではありません。
今のAI時代、むしろ積極的に使っていくべきです。
大事なのは、「使い方」。
- 重要な判断は、AIだけに任せない
- 出力結果は、必ず人間が確認する
- 「根拠」や「出典」を求める習慣をつける
- AIが苦手なタスク(事実確認、論理問題)では、特に注意する
- 混同行列で「どう間違えるか」を確認する
- AUCで「全体的な性能」を把握する
- 偽陰性(見逃し)が致命的な場面では、判定を甘めに設定する
こういう「付き合い方」を知っていれば、AIはすごく便利な道具になります。
数学的に言うと、これは「リスク管理」の考え方なんです。
完璧を目指すんじゃなくて、「どこでリスクが高まるか」を知って、そこに人間の確認を入れる。
そうすることで、全体の期待損失を下げられるというわけです。
数学観点から見えてくること
「精度90%」っていう数字の裏には、いろんな前提や条件が隠れてます。
数学の視点で見ると、こんなことが見えてきます。
確率は「平均」であって「保証」じゃない
90%正解でも、次の1回が正解かどうかは分からない。確率論の基本ですね。誤りの「重み」を考えないと、リスクは測れない
期待損失の計算では、誤りの確率だけでなく、1回の誤りがもたらす損失の大きさも考える必要がある。これが統計学の考え方。精度だけでは「どう間違えるか」が分からない
混同行列を使うと、偽陽性(空振り)と偽陰性(見逃し)が区別できる。どっちが重いかは、使う場面によって変わる。全体的な判定能力はAUCで測る
AUCは、判定の閾値に依存せず、AIの全体的な性能を一つの数字で表してくれる。0.9以上なら優秀、0.5ならコイン投げと同じで全ての結果は偶然。タスクごとに性能が違うのは、データの「分布」が違うから
AIは訓練データに依存するので、データが偏ってると性能も偏る。「分からない」と言えない設計は、確率的生成の宿命
AIは「次に来る言葉の確率」を計算してるだけなので、低確率でも何かしら出力する。
数学を知ると、「なんで90%なのに不安なんだろう」っていう違和感の正体が見えてくる。
それって、すごく大事なことだと思うんです。
AIを使うときに「ちょっと待てよ」って立ち止まれる。
その感覚を持つためには、数学的な視点が役立つんですね。
混同行列やAUCみたいな指標を知っていると、「精度90%」っていう数字の裏側が見えてくる。
そうすると、AIとの付き合い方も変わってくる。
完璧を求めるんじゃなくて、「どこに注意すればいいか」が分かるようになるんです。
関連する数学分野:確率論、統計学、期待値と分散、リスク評価、ベンチマーク評価指標、混同行列、ROC曲線、AUC(曲線下面積)、適合率・再現率