
「全部やらなきゃダメなの…?」という戸惑い
書店のビジネス書コーナーで『AI時代に必須の数学』みたいな本を手に取ると、目次にずらっと並んでるんですよね。線形代数、微積分、統計学、確率論、最適化理論…。
「これ、全部やらないと始められないの?」って思った瞬間、そっと棚に戻した経験、ありませんか。
実際、多くの企業が「数学的知識の不足」をAI導入の障壁として感じているようです。
でもこれ、よく見ると「何をどこまで学べばいいかわからない」っていう混乱の方が大きいんじゃないかって思うんですよね。
すべてが同じ重要度というわけではありません。
しかし、どこから始めれば良いかを教えてくれる人は少ないのです。
今回はその「優先順序」を、できるだけ具体的に整理してみます。
すべての数学が「同じ必須度」ではない
教材の目次に騙されてる説
AIや機械学習の教材を開くと、たいてい最初の方に数学の章があります。
Andrew NgのMachine Learningコース(Coursera)でも、線形代数・微積分・統計の3つが「前提知識」として並んでるんですよね。
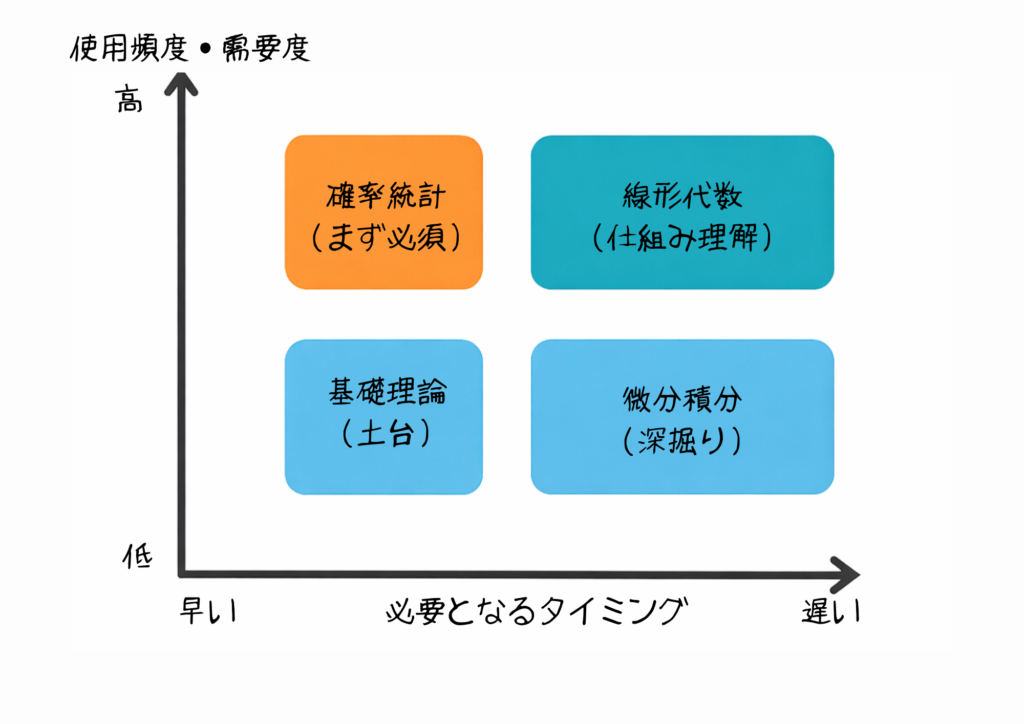
でも実際には、使う頻度も、必要になるタイミングも、全然違うんです。
たとえば統計学は、データを見る最初の段階からずっと使います。
一方で、微積分の連鎖律(チェーンルール)が必要になるのは、ディープラーニングの仕組みを深く理解したいときだけ。
つまり「全部必要」は正しいんだけど、「全部を今すぐ同時に学ぶ必要はない」んですよね。
「数式が読めない」という壁の正体
多くの人が、数学を学ぶ際に「記号が読めない」ことを障壁と感じているようです。
Σ(シグマ)とか、∫(インテグラル)とか、見た瞬間に難しいと感じるやつです。
でも実は、記号そのものが難しいのではなく、それが何を表しているかのイメージがないことが怖さの原因なんですよね。
たとえば「確率分布」って言葉だけ聞くと難しそうだけど、グラフで見ると「ああ、データのばらつき方を表してるのか」ってわかる。
そういう「具体的なイメージ」があるかどうかが、壁を感じるかどうかの分かれ目だと感じます。

使用頻度が教えてくれる優先順位
研究論文では統計・確率が頻繁に使われている傾向があるようです。
次いで線形代数、最適化理論と続きます。
これって、研究の最前線でも「よく使う順」があるってことなんですよね。
初学者が学ぶ順番も、この「使用頻度」を参考にするのが自然だと思うんです。
重要度を測る「3つのモノサシ」
じゃあ具体的に、どうやって優先順位をつければいいのか。ここでは3つの基準を使います。
① 使用頻度:実際にどれくらい登場するか
AI開発のツール(PyTorchやTensorFlow)の公式ドキュメントで、頻出するキーワードを調べると、統計・線形代数・最適化が上位に来ます。
たとえばPyTorchの torch.nn.Linear は線形代数、torch.optim.SGD は最適化理論に関係してる。
つまり「コードを書くときに、実際に触れる頻度」が高い分野ほど、早めに押さえておくと楽なんですよね。
これは、普段コードを書かない人にとっても「AIを使いこなすための地図」になります。
なぜなら、統計・線形代数・最適化は、ツールの内部で何が起きているかをざっくり理解する「共通言語」になっているからです。
ここを押さえることで、書籍やサイトで調べ物をするときなど、何の話をしているのかをぐっとイメージしやすくなります。
② 理解の土台度:他の分野を学ぶ前提になるか
線形代数は「全てのモデルの基盤」だと、Deep Learning Book の序章にも書かれています。
たとえば、PCA(主成分分析)を理解するには、固有ベクトルの概念が前提になる。
つまり「先に学んでおくと、後の学習がスムーズになる」分野があるんです。
これが「土台度」。
③ 実務での影響度:知らないとミスを招くか
統計的検定を誤解したまま A/Bテストを実施して、間違った施策を選んでしまう …
こういう失敗例は、実務でもちょこちょこ聞く話です。
つまり「知らないと、意思決定を間違える可能性がある」分野は、重要度が高い。
これが「影響度」です。
この3つのモノサシで見たとき、優先順位はどうなるのか。次から具体的に見ていきます。
【重要度★★★】まず押さえるべき必須3分野
第1位:統計学・確率論
統計学とは何か
統計学とは、データの「ばらつき」や「不確実性」を数値で測り、そこから意味のあるパターンや傾向を読み取る学問です。
確率論は「偶然」を数学的に扱う理論で、統計学の土台になっています。
なぜ最重要なのか
AIは大量のデータから学習するので、そのデータをどう読むか、どう評価するかが全ての土台になるんですよね。
機械学習モデルの評価指標(AUC、交差検証、p値など)も、全部統計の考え方が入ってます。
つまり「データを見る目」そのものが、統計学なんです。
押さえておきたい単元
- 確率分布(正規分布、ベルヌーイ分布など):データがどんな形で分布しているかを表す
- 期待値と分散:データの「中心」と「ばらつき」を数値化したもの
- ベイズ更新:新しい情報を得るたびに予測を修正していく考え方
- 仮説検証(帰無仮説、有意水準):データから結論を導く際の判断基準
数式としては複雑に見えるかもしれないけど、イメージとしては「データの形を読む」「予測の信頼度を測る」という感覚です。
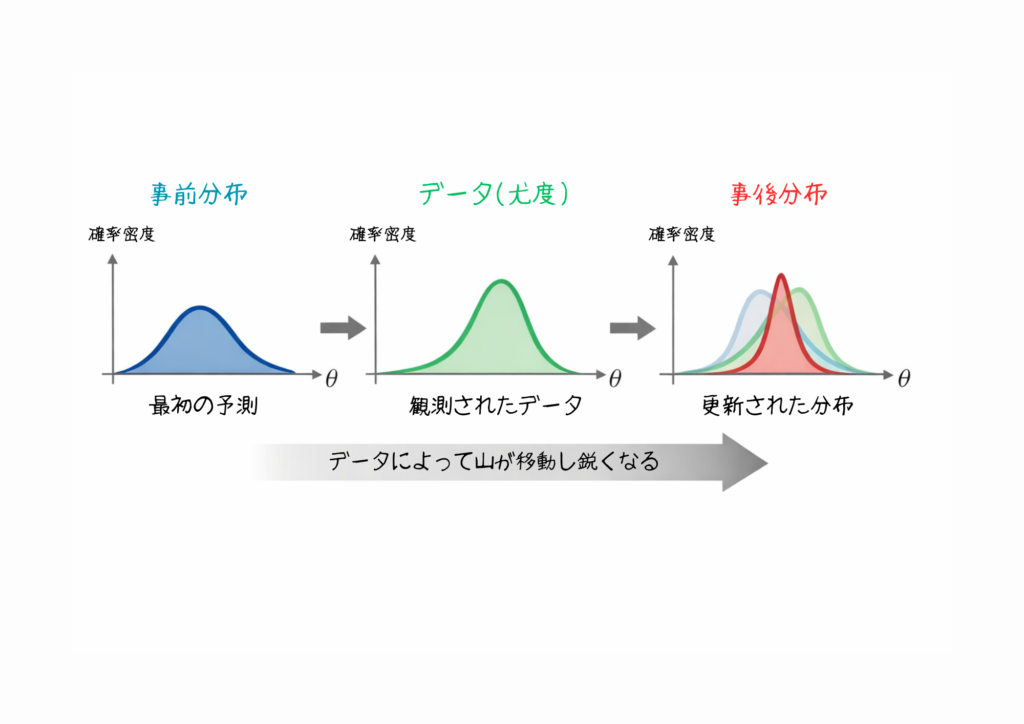
具体例:ベイズ推定で予測の信頼度を可視化
ある製品の購入確率を最初は 0.2 と仮定していたとします。
実際に30件の訪問があって、そのうち8件が購入したとき、ベイズ更新を使うと事後確率は約 0.27 に上がります(事前分布をBeta(1,4)と仮定した場合の例)。
これ、単なる計算じゃなくて「データが増えるごとに、予測の精度が上がっていく」プロセスを数値で追えるってことなんですよね。
ベイズ推定の式は以下のように表されます。
事後確率 ∝ 事前確率 × 尤度
「∝」は「比例する」という意味で、「新しいデータを見たあとの確率は、元の予測とデータの一致度で更新される」ってことを表してます。
こういう「確率的な視点」があると、AIの予測を「100%正しい答え」としてではなく、「信頼度付きの推定」として扱えるようになる。これが統計学の力です。
なお、こちらは統計学を学ぶほとんどの人が訪れるであろう、鉄板サイトです。
第2位:線形代数
線形代数とは何か
線形代数とは、ベクトル(向きと大きさを持つ量)と行列(数を格子状に並べたもの)を使って、データの変換や関係性を扱う数学の分野です。
なぜ2番目に重要なのか
ニューラルネットワークの計算は、ほぼ全て「行列の掛け算」で表現されます。
入力データをベクトルとして扱い、重み行列を掛けて、次の層に渡していく。
この繰り返しが「学習」なんですよね。
つまり「AIの心臓部」が線形代数。
ここを理解していると、モデルの構造が「なんとなく」じゃなくて「ちゃんと」見えるようになります。
押さえておきたい単元
- ベクトルと行列:向きと大きさ(ベクトル)、数の表(行列)の基本
- 行列の積:データの変換を表す計算
- 固有値と固有ベクトル:データの本質的な方向を見つける概念
- 特異値分解(SVD):データの重要な特徴を抽出する手法
計算の手順を全部覚える必要はないんです。
大事なのは「行列は変換を表してる」っていうイメージ。
イメージで掴むコツ
たとえばベクトルは「向きと大きさ」を持った矢印。
行列は「その矢印をどう変形するか」を決めるルール。
3Blue1Brownの「Essence of Linear Algebra」シリーズ(YouTube: 日本語版あり)を見ると、このイメージが視覚的にわかって、非常に納得できます。
計算式を追うより、動く図を見る方が早いんですよね。

第3位:微分・最適化
微分と最適化とは何か
微分とは、ある値が少し変化したときに、結果がどれだけ変わるかを調べる計算です。
最適化とは、誤差を最小にする(または目標を最大化する)ための調整方法のこと。
勾配(gradient)は「どの方向に進めば改善するか」を示す値で、微分によって計算されます。
なぜ3番目なのか
AIの「学習」は、誤差を小さくするようにパラメータを調整していくプロセスです。
この「どっちに調整すればいいか」を教えてくれるのが勾配で、それを計算するのが微分。
勾配降下法(Gradient Descent)は、ほぼ全ての学習アルゴリズムの根幹です。
押さえておきたい単元
- 偏微分:複数の変数があるとき、一つずつ変化を見る計算
- 勾配ベクトル:どの方向に進めば誤差が減るかを示す矢印
- 学習率:一度にどれだけ調整するかの「歩幅」
- モーメンタム、Adam などの最適化手法:効率よく学習するための工夫
学習のイメージ
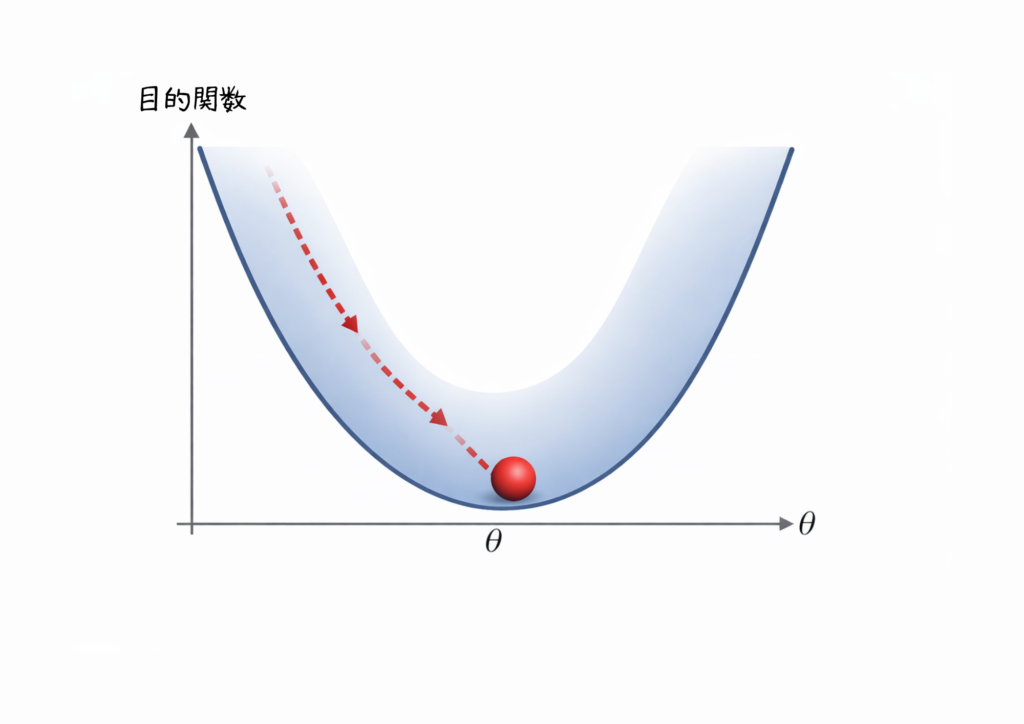
誤差関数(≒ 目的関数)を「山の高さ」だと思ってください。
今いる場所(今の誤差)から、一番急な下り坂の方向に少しずつ進んで降りていく(誤差を小さくしていく)。
それが勾配降下法です。
AIの「学習」とは「誤差を小さくしていくこと」
式で書くと以下のように表されます。
パラメータ(新) = パラメータ(旧) − 学習率 × 勾配
「学習率」は「一歩の大きさ」、「勾配」は「どっちに進むか」を表してます。
手計算する必要は全くないけど、この「坂を下るイメージ」があると、学習が進まないときに「学習率が大きすぎるのかな」とか「勾配が消えてるのかな」って考えられるようになります。
【重要度★★☆】次のステップで学びたい分野
第4位:情報理論
情報理論とは何か
情報理論とは、「情報量」を数値で測る学問です。
エントロピー(情報量の期待値)は「データの『意外さ』をビットで測る」概念で、よく起こることは情報量が少なく、珍しいことは情報量が多くなります。
KLダイバージェンスは「2つの確率分布がどれだけ異なるか」を測る指標です。
どんなときに必要?
ディープラーニングの正則化手法や、生成モデル(VAE、GANなど)を理解するときに出てきます。
「情報量」を数値で測る考え方が、モデルの設計に使われてるんですよね。
押さえる単元
- エントロピー(情報量の期待値)
- KLダイバージェンス(分布間の距離)
- 相互情報量
第5位:微積分(発展)
発展的な微積分とは
微積分の発展編では、連鎖律(チェーンルール)という「関数が重なったときの微分の計算方法」を扱います。
これは、ニューラルネットワークの層が重なったときに、誤差がどう伝わるかを計算するために使われます。
どんなときに必要?
バックプロパゲーション(誤差逆伝播)の数式的な裏付けを理解したいとき。
多変数関数の連鎖律が出てきます。
基本的な微分は第3位で押さえてるので、ここでは「層が重なったときの計算」に焦点を当てます。
実装はライブラリがやってくれるので、概念だけ押さえておけば十分です。
【重要度★☆☆】専門特化時に必要になる分野
第6位:グラフ理論
どんなときに必要?
推薦システム、ソーシャルネットワーク分析、知識グラフなど、「つながり」を扱うAIで登場します。
たとえばページランク(Googleの検索順位アルゴリズム)は、グラフ理論の中心性指標を使ってます。
第7位:集合論・論理学
どんなときに必要?
ルールベースAI、知識ベースシステム、推論エンジンなど、古典的なAI手法で使われます。
最近のディープラーニング中心の流れでは、あまり前面には出てこない気はします。
ただし「AIの推論とは何か」を哲学的に考えるときには、論理学の視点が役立ちます。
重要度順に学ぶ、具体的ロードマップ
なぜ統計学が必要なのか
統計学は「数式が少なく、直感的にイメージしやすい」のが最大の強みです。
ヒストグラムや箱ひげ図を見るだけで、データの傾向がわかる。
しかもビジネスの現場で即活用できます。
A/Bテスト、売上予測、顧客セグメンテーション…全部、統計の考え方がベースにあるんですよね。
統計スキルがプロジェクト成功に寄与するという報告もあります。
おすすめの入り口
- 『統計学が最強の学問である』(西内啓)
- Khan Academyの統計コース(無料、日本語字幕あり)
- 統計WEB
高度な確率論は後回しでOK。
まずは「平均・分散・標準偏差」から。
視覚的に学ぶことの効果
計算問題集などを解く必要はありません。
大事なのは「ベクトルは向き、行列は変換」というイメージ。
視覚的な教材が理解を助けると言われています。
おすすめの入り口
- 3Blue1Brownの「Essence of Linear Algebra」シリーズ(YouTube: 日本語版あり)
- 『プログラマのための線形代数』(平岡和幸、堀玄)
手計算の演習は省略して、図解中心で進めるのがコツです。
目的を持って学ぶ重要性
微分を単独で勉強すると、「何のためにやってるんだっけ?」ってなりがちです。
だから「勾配降下法を理解するために微分を学ぶ」という順番がおすすめ。
目的が明確だと、モチベーションが続くんですよね。
おすすめの入り口
- Andrew NgのMachine Learningコース(Coursera)Week 1〜2
- 『ゼロから作るDeep Learning』(斎藤康毅)
コードと一緒に動かしながら学ぶと、「ああ、この式がこの処理に対応してるのか」って実感できます。
「全部やらなきゃ」から「順番にやればいい」へ
最初に戻ると、書店で見た目次の「全部」は、確かに全部大事なんです。
でも「今すぐ全部」ではなく、「段階的に、使う順に」学べばいい。
- 統計学で「データを見る目」を養って
- 線形代数で「AIの構造」を理解して
- 微分で「学習の仕組み」を掴む
この3つを押さえたら、もう「AIの数学がわからない」っていう状態ではなくなってるはずです。
そこから先は、自分が深めたい領域に応じて、情報理論やグラフ理論を足していけばいい。
大事なのは「完璧に理解すること」ではなく、「見え方が変わること」なんですよね。
数学は資格試験ではなく、視点を広げる道具。
そう思えたら、学ぶハードルはぐっと下がるはずです。
数学観点のまとめ
- 統計学・確率論は、「データの不確実性を定量化」する視点
-
AIの予測を「確率的な推定」として扱えるようになる。
- 線形代数は「変換」の視点
-
ニューラルネットワークの各層が「データをどう変形しているか」が見えるようになる。
- 微分・最適化は「改善の方向性を探す」視点
-
学習が「誤差の坂を下る」プロセスだと理解できる。
この3つの視点があると、AIはブラックボックスではなく、「数学的なプロセスの組み合わせ」として見えてくる。
それが、数学を学ぶ一番の価値だと思います。
関連する数学分野:統計学、確率論、線形代数、微分積分学、最適化理論、情報理論、グラフ理論、集合論、論理学