同じ相談なのに空気が変わる
ChatGPTに同じ相談をしているのに、聞き方を少し変えただけで返事の温度感まで変わることないですか?
たとえば「この文章を直して」と頼むと、無難に整った返事が返ってくる。 でも「この文章を、やわらかく失礼のない感じに直して」と頼むと、急に丁寧な言い回しが増える。 逆に「率直に、問題点だけ指摘して」と言うと、同じ文章を見ているはずなのに、返事はかなり厳しめになる。
内容は同じでも、足した一言で返事の向きが変わる。 AIを使っていると、この揺れはかなり身近です。
ただ文脈を読んでいるだけでは足りない
AIは入力された文章を手がかりにして、次に続く言葉を選んでいるわけですが、ここで一つ不思議があります。
なぜ「やわらかく」や「率直に」のような一語が、返事全体の雰囲気まで変えるのでしょうか。
AIがその単語を見ているから、という説明だけでは少し粗い。 見てみたいのは、その単語が返事の方向をどれくらい押しているのかです。
「やわらかく」は、丁寧で配慮のある返事に寄せる手がかりになる。 「率直に」は、遠回しな表現を減らして指摘を前に出す手がかりになる。 「箇条書きで」は、文章の形そのものを変える手がかりになる。
一つひとつの言葉は、返事を直接決めるスイッチではありません。 返事の方向に力を加える小さな手がかりとして働いている、と読めないでしょうか。
その一語が返事をどちらへ押すか
ロジスティック回帰という見方で、この現象を解釈できるかやってみます。
ロジスティック回帰は、いくつかの手がかりから「ある結果になりやすいか」を確率で見る小さな模型です。 ここでは「返事がやわらかい雰囲気になるか」を結果として置いてみます。
もちろん、ChatGPTそのものがロジスティック回帰で動いている、という話ではありません。 実際の言語モデルはもっと大きく複雑で、単語を高次元の情報として扱います。
それでも、聞き方で返事が変わる感覚をつかむための模型として使うと、見えるものがあります。
「やわらかく」「初心者向けに」「専門用語を控えて」のような言葉は、やわらかい返事の確率を上げる側に働きそうです。 一方で「結論だけ」「厳しめに」「問題点を指摘して」のような言葉は、別の方向へ押すかもしれません。
プロンプトの言葉は飾りではなく、返事の確率を少しずつ押し上げたり、押し下げたりする材料として眺められます。
ほかのAIあるあるにも同じ見方が残る
この見方を持つと、プロンプト改善は「言い回しの暗記」から少し離れます。
返事が思ったより冷たいなら、丁寧さに寄せる手がかりが足りなかったのかもしれない。 返事が長すぎるなら、短さに寄せる手がかりが弱かったのかもしれない。 返事が抽象的なら、具体例や場面設定に寄せる手がかりを入れる余地がある。
逆に、手がかりを入れすぎると衝突します。 「やさしく説明して」と「結論だけ短く」は両立することもありますが、場合によっては片方の力が弱まります。 「初心者向けに」と「専門的に厳密に」も、どちらを強めたいのかを決めないと、返事が中途半端になりやすい。
同じ相談でも返事が揺れるのは、AIの気分が変わったからではありません。 こちらが置いた言葉が、返事の方向をどちらへ押しているか。 そう考えると、調整する場所が見えてきます。
式に書き直してみる
「やわらかい返事になる確率」を $p$ と置いてみます。 $p$ は 0 から 1 のあいだの数で、1 に近いほどやわらかい返事になりやすい、という意味です。
プロンプトに含まれる手がかりを、$x_1, x_2, x_3$ と書きます。 たとえば $x_1$ は「やわらかく」という言葉があるか、$x_2$ は「結論だけ」という言葉があるか、$x_3$ は「初心者向けに」という言葉があるか、だと思えば十分です。
ロジスティック回帰の形で見てみると、確率はこう書けます。
$\beta_0$ は、何も指定しないときの基本の寄り方です。 $\beta_1$ や $\beta_2$ は、それぞれの手がかりが返事の方向をどれだけ押すかを表します。
もし $x_1$ が「やわらかく」という手がかりで、$\beta_1$ が正なら、その言葉は $p$ を上げる方向に働きます。 つまり、やわらかい返事になりやすくなる。
もし $x_2$ が「結論だけ」という手がかりで、$\beta_2$ が負なら、その言葉は $p$ を下げる方向に働きます。 つまり、やわらかさよりも簡潔さや断定感に寄りやすくなる。
式の中身は、言葉ごとの小さな力を足し合わせたものです。 合計が大きくなるほど確率 $p$ は 1 に近づき、小さくなるほど 0 に近づく。
ここで大事なのは、確率の変わり方が一直線ではなく、S字になることです。 手がかりが弱いあいだは、言葉を少し足しても返事はあまり動かない。 でも、ある境目の近くでは、一語の追加で返事の温度が大きく変わります。
この式で見てみると、プロンプトの一語一語は「お願いの飾り」ではなく、返事の向きを押す部品として読めます。
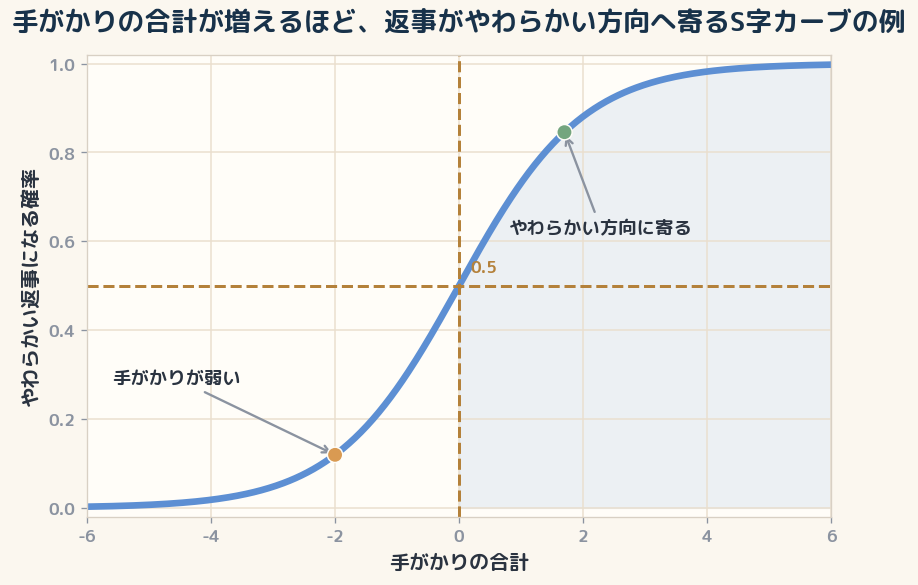
図では、横軸を「手がかりの合計」、縦軸を「やわらかい返事になる確率」として描いています。 手がかりが増えるほど確率は上がりますが、途中でぐっと立ち上がり、最後は 1 に近づいて頭打ちになります。 だから、ほんの一語で急に返事が変わる場面は、S字曲線の立ち上がり部分にいると読むことができます。
実際には、LLM内部では多層の変換を通じた複雑なスコア計算をしており、ここでは『一次近似の玩具モデル』としてロジスティック回帰を置いています。
言葉で確率を設計する
次にAIの返事が思った方向とずれたとき、「言い方が悪かった」で終わらせなくてもいい。 どの手がかりが足りず、どの手がかりが強すぎたのかを見直せます。
言葉を足す、削る、順番を変える。 それはお願いの文章をきれいにする作業というより、返事の方向を押す材料を設計する作業です。
同じAIなのに、聞き方で返事が変わる。 その揺れを「言葉が確率を動かしている」と読めるなら、プロンプトはただの入力文ではなくなります。 狙った返事に近づけるための、小さな実験装置として扱えるかもしれませんね?